

데이터 어플리케이션 셀에서는 머신 러닝을 통해 반복 작업을 자동화하여 사람은 사람만이 할 수 있는 일에 집중할 수 있는 환경을 만들어 나가고 있습니다. 사람이 직접 하려면 수천시간이 걸리는 게임 밸런싱을 강화학습을 통해 자동화한 경험과 업데이트 이전에 유저의 경험을 정량화하여 비지니스적인 의사 결정에 도움을 주었던 경험을 공유해보려고 합니다.
#생각보다도 퍼즐 게임의 밸런스는 중요합니다.

재미있는 퍼즐 게임을 만들기 위해서는 정말 많은 요소들이 필요합니다. 용감한 쿠키처럼 귀여운 캐릭터도 필요하고, 재미있는 맵들, 매력있는 스토리, 이외에도 사용하기 편한 UI등 수많은 요소들이 조화를 이루어야 좋은 게임이 만들어 집니다. 그런데, 유저들이 정말 즐길 수 있는 게임을 만들기 위해서는 밸런싱에 대한 이야기를 빼 놓을 수가 없습니다. 특히 쿠키런: 퍼즐 월드(이하 퍼즐 월드)는 같은 색을 가진 젤리를 3개 매칭해 나가면서 퍼즐을 푸는 3매치 게임인 만큼 적절한 밸런스를 잡는 것은 매우 중요합니다. 만약 아이템을 사용하지 않으면 도무지 클리어할 수 없는 어려운 맵들만 등장 한다면 유저는 금방 질려서 게임을 떠나게 될 것 이고, 손쉽게 깨지는 난이도로 밸런스를 맞추어도 게임이 너무 시시해져서 이탈하게 될 것 입니다. 그러면 퍼즐 게임의 밸런스는 어떻게 잡을 수 있을까요?
#일단 플레이 해보기
퍼즐 월드의 맵들은 레벨 제작팀에서 제작이 되지만 사실 이 맵이 얼마나 어려운지, 클리어하는 데 몇 턴이 필요할 지는 만든 사람조차도 예상하는데 어려움이 있습니다.
워낙 다양한 장애물들과 쿠키들이 있기도 하고, 기본적으로 운에 의해 좌우되는 요소를 가지고 있는 게임이기 때문에 맵을 단순히 눈으로 보는 것 만으로는 밸런스를 예측할 수 없습니다.
그러므로 밸런스를 정하는 유일한 방법은 맵을 제작하는 분들이 직접 플레이를 해보고 해당 맵을 클리어하는 데에 평균적으로 몇 턴이 필요한 지를 체크하는 방법 뿐이었습니다.
게임을 플레이하는 게 일이라니 좋아 보이지만 실제로는 그리 즐거운 작업이 아닙니다.
앞서 이야기했듯이 많은 부분이 랜덤 요소에 좌우되기에 밸런싱을 정확하게 진행하기에 한 두판의 플레이 경험은 전혀 충분하지 않습니다.
적어도 수십 판 정도는 플레이를 해 보아야지만 어느 정도 정확하게 밸런싱을 할 수 있으며 심지어 퍼즐 월드에는 다양한 게임 모드와 독특한 개성을 가진 쿠키와 펫들이 있기 때문에 버프에 의한 효과들과 강화 보너스 그리고 조합 보너스까지 고려하면서 밸런싱을 진행해야 합니다.
또한 2020년 말 기준으로 퍼즐 월드에 약 1500개 가량의 맵들이 포함되어 있고 일주일 마다 30개의 신규 맵들이 등장하고 있으며 주기적으로 이탈률이 높은 맵들을 개선하는 작업 또한 병렬적으로 수행하고 있기 때문에 이 맵들을 모두 직접 플레이 하며 밸런싱 한다는 것은 엄청난 일을 필요로 합니다.
실제 수치로 계산을 해 본다면 현재 퍼즐월드에는 40종 가량의 쿠키와 1500개 정도의 맵, 그리고 강화 시스템이 있으므로 40(쿠키 수) * 1500(맵 수) * 3(테스트할 버프 수) * 64(한 조합당 플레이 횟수) = 1152만 판 정도의 플레이를 수행하여야 합니다.
한 게임을 플레이하는 데 1분 정도가 걸린다고 가정하여도 모든 조합을 시도해보려면 꼬박 8000일이 걸리게 됩니다!
#강화학습을 이용해서 해결해 볼 수 있지 않을까?

퍼즐 월드는 기본적으로는 같은 색을 가지는 젤리를 3개 매칭시켜 장애물을 제거해 나가는 게임이지만 4개 이상의 젤리를 매칭하면 위와 같이 부스터가 생성됩니다. 부스터는 그 자체만으로도 강력한 효과를 가지고 있는 동시에 2개의 부스터를 서로 매칭 시키면 더욱 강력한 효과를 발휘하게 되므로 퍼즐 월드를 잘 하기 위해서는 이 부스터들을 적절히 조합하고 사용하여야만 합니다. 그런데 이렇게 복잡한 규칙의 퍼즐 게임을 플레이하는 봇을 규칙 기반으로 만드는 것은 굉장히 어렵습니다. 젤리의 패턴을 모두 기록하는것도 쉽지 않으며, 워낙 다양한 장애물들이 있기 때문에 사람처럼 유연한 플레이를 하도록 만들기는 쉽지 않습니다. 심지어 매 번 게임이 업데이트 될 때마다 새로운 로직을 추가해 주어야 하는 번거로움이 있기 때문에 직접 봇을 만드는 것은 그리 좋은 생각이 아닙니다. 그러나, 강화 학습은 스스로 시행 착오를 거치면서 배워 나가는 방식이기 때문에, 강화학습을 이용한다면 복잡한 규칙을 직접 알려줄 필요도 없고 생각하지 못한 예외적인 상황을 처리하지 못해 골치가 아플 일도 없습니다.
#학습 절차

그런데 강화학습을 통해 이 문제를 해결하기 위해서는 몇 가지 준비물이 필요합니다. 강화 학습은 직접 시행착오를 겪어 보면서 학습을 해 나가는 방법이기 때문에, 게임을 플레이 하는 사람(Agent)와 게임이 진행될 환경(Environment)이 필요합니다. Agent의 경우에는 게임을 플레이하는 사람 처럼 주어진 게임판의 상태(State)를 보고 이 상황에서 어떤 행동(Action)을 취할 것인지 결정을 해야 합니다. Enviroment에서는 Agent에서 결정한 Action을 바탕으로 게임판의 상태를 업데이트 하고, 행동에 대한 보상(Reward)을 다시 Agent에게 돌려 줍니다. 이 보상을 이용하여 Agent는 자신이 취한 Action이 좋았는지, 아니면 좋지 않았는 지를 판단하게 됩니다. 그러면, Agent에 대해 알아보기 전에 퍼블 봇의 Enviroment는 어떤 방식으로 구성되어 있을까요?
당연히 유저들이 플레이 하는 환경과 완전히 동일한 환경에서 Agent가 플레이를 하는 것이 가장 일반적이면서도 좋은 방법일 것입니다.
실제로도 대부분의 학습은 유저들이 플�레이하는 환경과 완전히 동일한 환경(Unity ML Agent)에서 진행이 되고 있지만 이 환경에는 치명적인 단점이 있습니다.
바로 속도가 느리다는 단점인데요, 아무래도 다양한 장애물들이 모두 들어있기도 하고 unity자체가 조금 느리기 때문에 학습에 오랜 시간이 소요되는 문제가 있습니다.
강화학습이 아닌 다른 ML 분야의 경우에는 대부분의 시간을 GPU를 사용하여 모델의 파라미터들을 업데이트 하면서 보내지만, 강화학습의 경우에는 Environment에서 플레이를 하는 데 대부분의 시간을 보냅니다.
성능을 개선하기 위해서는 ML 특성상 다양한 모델을 시도 해 보아야 하지만 실제 Unity환경에서는 한 번의 실험을 할 때마다 3일이 걸리기 때문에 그만큼 개발 속도가 느려지게 됩니다.
보다 빠르게 실험 결과를 얻고 지속적으로 모델을 개선해 나가기 위해서는 Unity 환경보다 빠른 속도로 게임을 돌릴 수 있는 Mock 환경을 Cython으로 제작을 했습니다.
물론 실제 게임에 포함된 장애물들과 맵들을 모두 그대로 재현하기에는 어려움이 있지만 그래도 게임의 가장 기본적인 요소인 3매치나 부스터 그리고 단순한 형태의 장애물들은 직접 구현을 했습니다.
테스트 결과 Unity에서는 한 번의 행동을 수행하는데 약 0.1초가 걸리는데 반해 Cython으로 제작한 Mock환경에서는 0.01초 이내에 한 번의 스텝(한 번의 Action)이 진행되기 때문에 반나절이면 학습의 결과를 얻을 수 있게 되었습니다.
따라서 모델을 개선하는 작업을 진행할 때는 이 Mock환경을 이용하고 있으며 실제 밸런싱을 진행할 때는 시간이 오래 걸리더라도 정확한 결과를 얻기 위해 실제 유니티 빌드에서 학습을 수행합니다.
다음으로 드디어 Agent에 대한 내용입니다. 먼저, 다��양한 강화학습 모델 중에서 퍼즐 봇에 사용되고 있는 모델은 Policy-Gradient 기반의 PPO(Proximal Policy Optimization)를 이용하고 있습니다. DQN과 같은 Value-Based한 모델을 이용해서 학습이 가능 하기는 하지만, 퍼즐 월드에서 DQN을 사용하기 위해서는 405개의 가능한 Action들에 대해서 Q-Value들을 계산해 나가야 하기 때문에 효율적이지 못합니다. 그러므로 고차원의 Action Space에서 더 잘 수렴하는 Policy-Gradient가 좋은 선택입니다. 또한 3매치를 잘 학습하기 위해서는 주변에 어떤 색의 젤리가 있는지를 살펴 보는 것이 중요한 데 이것은 이미지를 인식할 때 주변 픽셀들을 이용하는 것과 유사하므로 이미지 인식에 사용되는 ResNet을 Policy Network로 사용할 수 있습니다. 물론 게임의 상태는 게임판 위에 있는 젤리들의 상태(Visual Feature) 이외에도 현재 플레이중인 게임을 클리어하기 위한 목표나 현재 사용중인 쿠키, 남은 턴수 등에 대한 정보가 필요하기 때문에 이런 정보들은 별도로 처리하게 됩니다.
그런데, 이렇게 모델을 구성했을 때는 생각보다 잘 수렴하지 않는 문제가 있었습니다. 아무래도 강화학습 에이전트가 학습해야 하는 게임 자체가 복잡하기도 하고, 수행할 수 있는 Action의 수가 너무 많기 때문에 강화학습 에이전트가 잘 학습하지 못했었습니다. 사실 지금까지는 퍼즐 월드의 물리적 특성을 이용하지는 않았고 어떠한 문제에서도 적용 가능한 형태로 모델을 구성하였습니다. 그러므로 퍼즐 월드에서만 적용되는 몇 가지 특성들을 적절한 형태로 모델에 녹여 낸다면 훨씬 더 잘 수렴할 것이라는 것을 예상할 수 있습니다.
모델의 성능을 개선하는 데 가장 큰 도움을 준 특성은 사실 젤리의 색은 별로 중요한 것이 아니라는 점입니다. 젤리��의 색이 빨간 색인지 아니면 파란 색인지는 별로 중요한 것이 아니고, 같은 색의 젤리 3개를 일렬로 만들 수 있는 지에 대한 여부가 더 중요합니다.

그러므로 위에 있는 두 상태는 다른 색깔이지만 Agent의 입장에서는 완전히 동등한 상태라고 생각할 수 있고, 이 특성을 이용하게 된다면 Agent가 탐색해야 할 공간의 크기가 크게 감소합니다.
이렇게 입력되는 순서와는 상관 없이(Permutation Invariant) 같은 특성을 보이는 Feature들의 경우에는 한 가지 조합만 탐색해도 되므로, 탐색 공간의 크기가 1/(색깔의 수)! 만큼으로 감소하게 되고, 퍼즐 월드에서는 총 여섯가지 색의 젤리가 있으므로 탐색할 범위가 720분의 1로 줄어들게 됩니다.
두 번째로 사용한 퍼즐 월드만의 물리적 특성은 어떤 행동을 수행할 ��때 그 행동으로 인해 변화가 생기는 지점들의 위치를 미리 알 수 있으며 이 위치들을 모델로 바로 전달해 줄 수 있다는 점입니다.
모델을 이루고 있는 Neural Net은 당연히 처음에는 랜덤한 값으로 초기화가 되어 있기 때문에 특정한 행동을 수행했을 때 게임판에 어떠한 변화가 생기게 되는 지에 대해서는 전혀 예측을 하지 못합니다.
아무 것도 모르는 상태에서 수천만 번 젤리를 스왑해 보면서 아~ 같은 색깔의 젤리 3개를 일렬로 배치하면 터지는구나~, 이 부스터는 이렇게 터지는구나~와 같은 사실을 천천히 배워 나가게 되는데 반해서 우리는 이러한 사실들을 학습을 시작하기 전부터 알고 있으므로 이 정보들을 학습이 시작하는 시점부터 바로 모델에 전달해 줄 수 있습니다.
그러므로 모델은 3개를 매칭하면 젤리가 터지고, 부스터를 사용하면 이러이러한 모양으로 터진다는 사실을 알고 있는 상태로 학습을 시작할 수 있으며 불필요한 탐색을 수행하지 않게 되기 때문에 훨씬 더 빠르게 학습을 수행하게 됩니다.
물론 퍼즐 게임 특성상 랜덤성을 가지고 있기 때문에 직접 실행해보지 않고는 어떤 블록들이 터지는 지 정확하게 알 수 는 없지만 그래도 어느 정도 정확한 값을 전달해 주는 것 만으로도 성능 향상에 많은 기여를 할 수 있습니다.
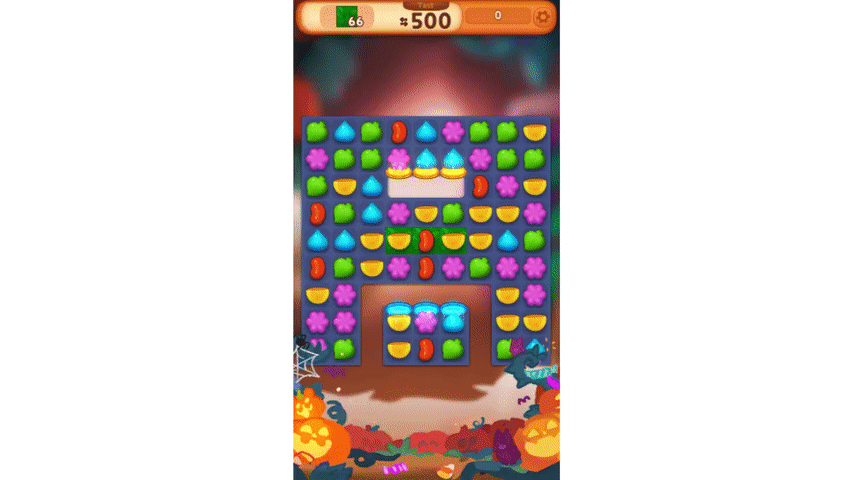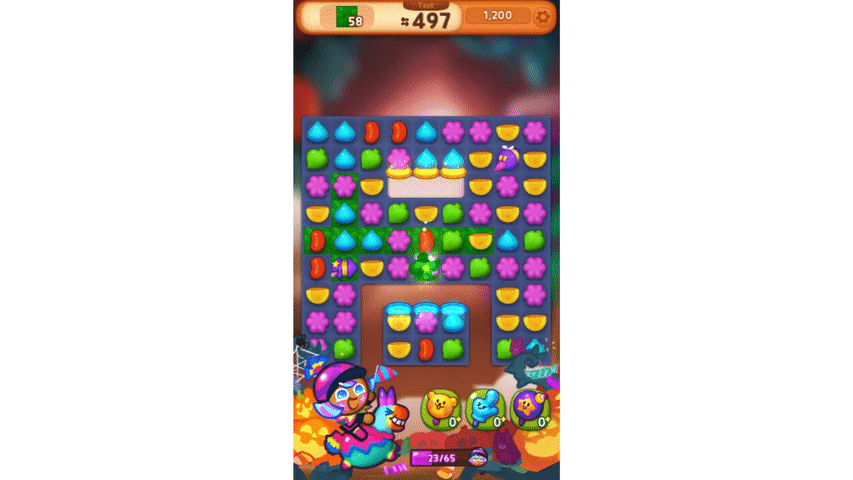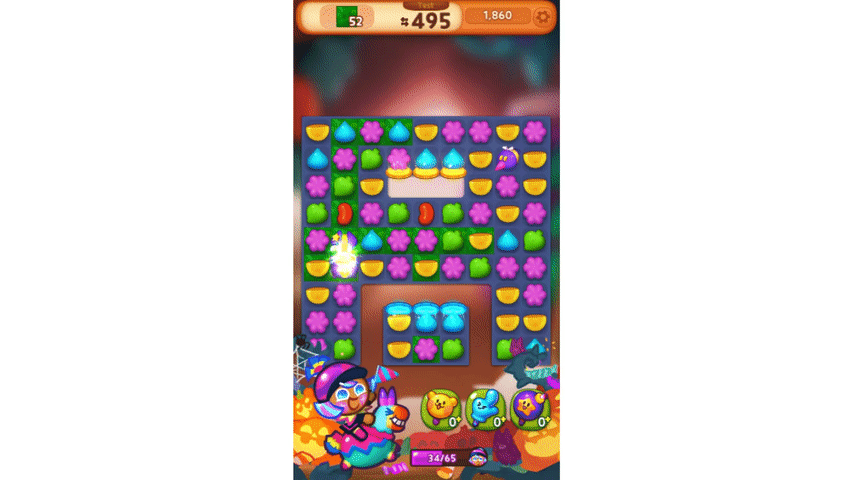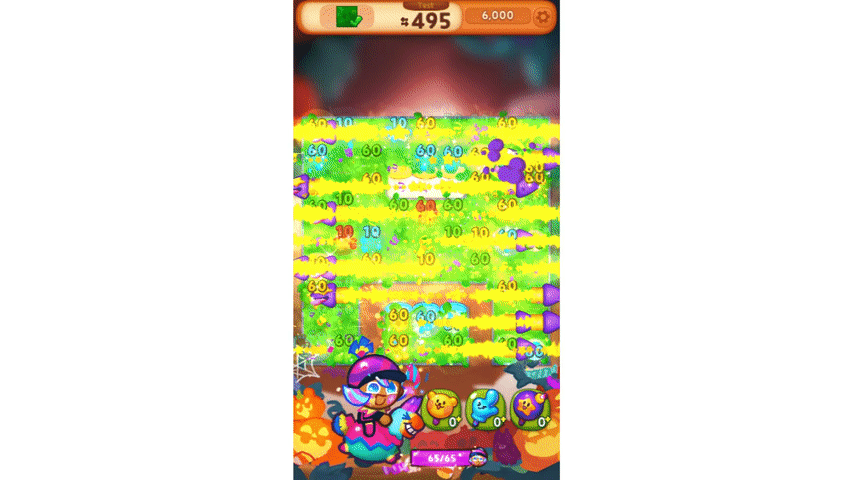
이렇게 만들어진 모델은 위 영상처럼 몇 수 앞을 내다보는 플레이를 보여 주기도 합니다.
게임을 기획할 때는 유저가 원하는 것을 세심하게 파악하면서도, 게임의 밸런스를 무너뜨리지는 않아야 합니다. 그런데, 사실 기획 단계에서는 게임에 어느 정도로 변화를 주는 것이 최선인지 알기가 매우 어렵고 많은 경우에는 감에 의존해서 의사 결정을 진행하는 경우가 많았습니다. 물론 적절하게 게임이 개선되는 경우도 있지만, 대부분의 게임들은 몇 차례의 추가적인 패치가 이루어 지기도 하고 심지어는 유저들에게 패치 내용을 알려주지도 않고 몰래 패치가 이루어지기도 합니다. 이러한 잦은 패치는 유저의 경험을 상당 부분 해치기 때문에 적절한 기획은 매우 중요합니다. 그런데 실제로 업데이트가 이루어지기 전에는 기획이 적절한지 알기 어렵다는 문제는 퍼즐 봇을 이용하면 해결할 수 있습니다. 퍼즐 봇을 단순히 게임을 플레이하는 봇이라는 관점에서 벗어나, 한 명의 유저라는 관점에서 바라보게 된다면 퍼즐 봇의 플레이 결과를 바탕으로 비지니스적인 의사 결정을 하는 데도 많은 도움을 줄 수 있었습니다. 가령 40종의 다양한 쿠키들중에서 특정 쿠키만 아주 강력한 효과를 가지고 있다면 유저들이 해당 쿠키만 구매하게 될 수 있을 수 있는데, 퍼즐 봇을 이용한다면 각 쿠키들이 얼마나 좋은지를 정량화할 수 있게 되어 쿠키들의 개성을 살릴 수 있는 방향으로 게임을 개선해 나갈 수 있었습니다. 이외에도 강화 시스템이 추가되면서 게임이 너무 쉬워질 수 있다는 우려가 있었는데, 퍼즐 봇을 이용한다면 강화시스템이 도입된 후 게임이 얼마나 쉬워지는지, 그에 따라서 재화 사용량과 매출은 어느 정도로 감소하는지에 대한 통찰도 미리 얻을 수 있었습니다.
퍼즐 게임을 제작하고, 운영하면서 발생하는 다양한 문제들을 강화 학습을 통해 해결할 수 있었습니다. 데이터 어플리케이션셀에서는 "Data-driven"이라는 미션 아래, 통계와 머신 러닝 등의 도구를 활용하여 게임 산업에서의 문제를 능동적으로 해결해 나가고 있습니다. 우리 팀과 함께 "Data-driven"으로 의사결정하는 조직을 만들어나가실 분을 적극적으로 기다리고 있으니 주저 말고 지원 부탁드립니다.
